概述
阅读源码是学习进阶必须越过的一步,同时也要学习其他人阅读源码的方式和经验,本文内容不全是个人做的比如图就是从网上偷来的,站在巨人肩膀上才能更好地让自己看到更多。
overview
spdlog的是一个支持多平台的日志库,使用十分方便。且既支持header-only version,也支持compiled version。header-only的全部代码都在项目的include文件夹下,直接将里面的内容copy到自己的项目里就能用。spdlog主要由logger(也包括async_logger)、sink、formatter、registry这四个部分组成,它们之间的基本逻辑结构如下图所示:
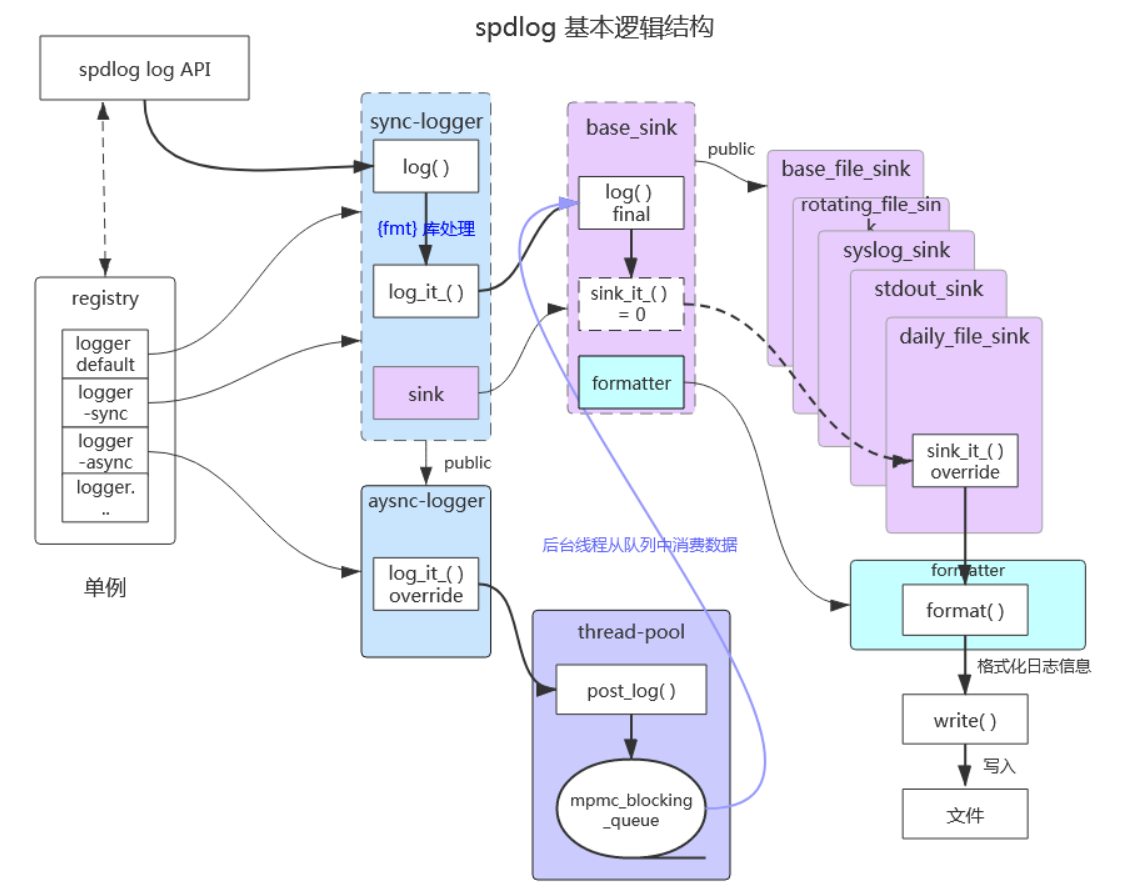
- spdlog log API —— 是建立在logger之上的,只是对logger使用的封装,目的只是为了能够像官网给的示例代码spdlog::info(“Welcome to spdlog!”);那样,让用户能够以最简单的方式使用spdlog打印出log。这是一种从用户使用维度出发的程序设计思想。
- logger —— 是spdlog开始处理日志的入口。sync-logger主要负责日志信息的整理,将格式化(通过第三方库fmt)后的日志内容、日志等级、日志时间等信息“整理”到一个名为log_msg结构体的对象中,然后再交给下游的sink进行处理。而对于async-logger,则是在将整理后的log_msg对象交给线程池,让线程池去处理后续的工作。
- sink —— 接收log_msg对象,并通过formatter将对象中所含有的信息转换成字符串,最后将字符串输出到指定的地方,例如控制台、文件等,甚至通过tcp/udp将字符串发送到指定的地方。sink译为“下沉”,扩展一下可以理解为“落笔”,做的是把日志真正记录下来的事情。
- formatter —— 负责将log_msg对象中的信息转换成字符串,例如将等级、时间、实际内容等。时间的格式和精度、等级输出显示的颜色等都是由formatter决定的。支持用户自动以格式。
- registry —— 负责管理所有的logger,包括创建、销毁、获取等。通过registry用户还可以对所有的logger进行一些全局设置,例如设置日志等级。
sync-logger
这部分的代码都在logger.h和logger-inl.h中,对应logger类。logger要做的事情就是将要记录的内容通过函数调用层层传递到,最后到sink。以logger中成员函数info两种调用情况为例,展示logger的调用过程。
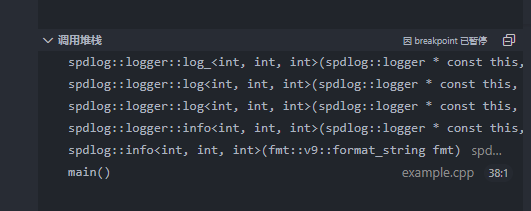
具体函数签名:
// 调用例如spdlog::info("Welcome to spdlog!");
// 或者spdlog::info(num);
template <typename T> void info(const T &msg)
{ log(level::info, msg); } // 确定log等级为info
// 调用例如spdlog::info("Support for floats {:03.2f}", 1.23456);
// 或者spdlog::info("Positional args are {1} {0}..", "too", "supported");
template <typename... Args> void info(format_string_t<Args...> fmt, Args &&...args)
{ log(level::info, fmt, std::forward<Args>(args)...); } // 确定log等级为info
template <typename T> void log(level::level_enum lvl, const T &msg)
{ log(source_loc{}, lvl, msg); } // 接着再确定日志调用的位置(文件、函数名、行号)
template <typename... Args>
void log(level::level_enum lvl, format_string_t<Args...> fmt, Args &&...args)
{ log(source_loc{}, lvl, fmt, std::forward<Args>(args)...); } // 接着再确定日志调用的位置(文件、函数名、行号)
template <typename T> void log(source_loc loc, level::level_enum lvl, const T &msg)
{ log(loc, lvl, "{}", msg); } // 因为spdlog::info(num);可以等价为spdlog::info("{}", num);,所以这里加了一个“{}”
template <typename... Args>
void log(source_loc loc, level::level_enum lvl, format_string_t<Args...> fmt, Args &&...args)
{ log_(loc, lvl, details::to_string_view(fmt), std::forward<Args>(args)...); } // 成员函数info两种调用过程都会汇集到此处logger的调用过程是层层传递的,传递过程中不断添加各种信息,最后两种方式的调用都汇集到log_函数中,log_函数实现如下:
// common implementation for after templated public api has been resolved
template <typename... Args>
void log_(source_loc loc, level::level_enum lvl, string_view_t fmt, Args &&...args) {
bool log_enabled = should_log(lvl);
bool traceback_enabled = tracer_.enabled();
if (!log_enabled && !traceback_enabled) {
return;
}
SPDLOG_TRY {
memory_buf_t buf;
#ifdef SPDLOG_USE_STD_FORMAT
fmt_lib::vformat_to(std::back_inserter(buf), fmt, fmt_lib::make_format_args(args...));
#else
fmt::vformat_to(fmt::appender(buf), fmt, fmt::make_format_args(args...));
#endif
details::log_msg log_msg(loc, name_, lvl, string_view_t(buf.data(), buf.size()));
log_it_(log_msg, log_enabled, traceback_enabled);
}
SPDLOG_LOGGER_CATCH(loc)
}首先判断是否需要记录日志should_log(lvl),以及是否需要traceback,如果都不需要则直接返回,判断逻辑是当前log等级是否大于logger的log等级。而traceback是spdlog的另一个功能,对我们理解spdlog的调用过程相关程度不高,可不必细究。至于fmt库将输出格式化,C++20中STL库有了自带的fmt和location,在学习之后可以自己试着写一个log库。
至此logger完成了它的主要工作,最后很剩下的工作就是把log_msg对象交给下游的sink进行处理了,就是上面最后一句代码“log_it_(log_msg, log_enabled, traceback_enabled);”要做的事。这部分代码如下:
// protected methods
SPDLOG_INLINE void logger::log_it_(const spdlog::details::log_msg &log_msg,
bool log_enabled,
bool traceback_enabled) {
if (log_enabled) {
sink_it_(log_msg);
}
if (traceback_enabled) {
tracer_.push_back(log_msg);
}
}
SPDLOG_INLINE void logger::sink_it_(const details::log_msg &msg) {
for (auto &sink : sinks_) {
if (sink->should_log(msg.level)) {
SPDLOG_TRY { sink->log(msg); }
SPDLOG_LOGGER_CATCH(msg.source)
}
}
if (should_flush_(msg)) {
flush_();
}
}
SPDLOG_INLINE void logger::flush_() {
for (auto &sink : sinks_) {
SPDLOG_TRY { sink->flush(); }
SPDLOG_LOGGER_CATCH(source_loc())
}
}log_it函数又进一步调用了sink_it函数。在sink_it函数中,首先遍历了sinks_中的所有sink,在把msg交由每个sink去处理。
sinks并不是一个类,而是一系列类,以基类-派生类形式组织,一个sink派生类代表了一种输出log消息方式,输出目标可以是普通文件stdout、stderr,或者syslog等等。sink系列类主要负责从logger接收用户log消息,按指定模式(pattern)进行格式化(format),得到一条完整的、格式化后的log消息,然后将其写到目标文件。sink系列类的实现,全部位于include/spdlog/sinks目录。
sinks_是logger的成员变量,其声明为“std::vector<sink_ptr> sinks_;”。可以看出一个logger是可以对应多个sink的,同时sink实际上还是指针形式保存在logger中的,意味着也可以存在多个logger都指向同一个sink的情况。这样日志的输入端(logger)和输出端(sink)就解耦了。这样方便我们扩展,比如现在想让日志同时输出到文件和控制台,只需要在创建logger的时候把两个sink都添加进去就可以了。
sink_it_函数中还调用了flush\_函数,这个函数的作用是让所有sink都进行一次flush操作。前面的sink->log(msg)这是写入了缓冲区,而sink->flush()是将缓冲区的内容进一步写入到文件或者控制台等最终目的地。而且在sink_it函数调用flush_函数之前,还调用了should_flush_函数,函数中判断了msg的等级和flush_level_的关系,如果msg的等级大于flush_level_则返回true,否则返回false。这么做的目的是减少不必要的flush操作。例如我们像保存info及其以上等级的日志,但是绝大多数时候我们并会实时地查看info级别的日志,但是error级别的日志我们却希望能够及时展示出来。那么我们可以将flush_level_设置为error,这样只有error级别的日志才会进行flush操作。
同步工厂方法
通常,一个工厂方法创建一种对象,如果想创建不同类型的对象,就传入参数,工厂方法内部进行判断后创建不同类型对象。synchronous_factory的精妙之处在于,函数参数用来创建对象,模板参数用来指定要创建的类型(有关的部分)。
logger_name对于registry全局注册表来说,是唯一标识logger对象的。
这里有一个潜在的约定,所有工厂方法必须实现一个static create方法,通过模板参数Sink创建不同类型Sink派生类对象,然后绑定到新建的logger对象,从而实现不同的功能。
// Default logger factory- creates synchronous loggers
class logger;
struct synchronous_factory
{
template<typename Sink, typename... SinkArgs>
static std::shared_ptr<spdlog::logger> create(std::string logger_name, SinkArgs &&... args)
{
auto sink = std::make_shared<Sink>(std::forward<SinkArgs>(args)...); // 模板参数Sink决定了要具体Sink类型
auto new_logger = std::make_shared<spdlog::logger>(std::move(logger_name), std::move(sink)); // 用logger name及sink来创建logger对象
details::registry::instance().initialize_logger(new_logger); // 初始化logger, 并添加到全局注册表
return new_logger;
}
};
async-logger
async-logger的代码在asyn_logger.h和async_looger-inl.h中,对应async_logger类。async_logger继承自logger,前面关于接受日志内容整理log_msg对象中的工作照常做,将对sink的调用(包括sink->log(msg)和sink->flush())都交由线程池去执行了,由此便实现了异步。代码如下:
void spdlog::async_logger::sink_it_(const details::log_msg &msg)
{
if (auto pool_ptr = thread_pool_.lock())
{
pool_ptr->post_log(shared_from_this(), msg, overflow_policy_);
}
else
{
throw_spdlog_ex("async log: thread pool doesn't exist anymore");
}
}
// thread_pool_ 的声明
std::weak_ptr<details::thread_pool> thread_pool_;线程池通过pool_ptr->post_log(shared_from_this(), msg, overflow_policy_);这句代码持有了当前asyn_logger的shared_ptr。那这样asyn_logger就不能再以shared_ptr的形式持有线程池了,因为会存在交叉引用带来的内存泄露问题。所以这里使用weak_ptr来持有线程池。毫无疑问,async_logger实现的重点是线程池。
线程池里面要有一个多生产多消费的线程安全队列,用来存放日志内容。可以有多个async_logger(即生产者)向里面生产日志,又同时又多个线程(即消费者)从里面消费日志。这个队列的容量应该是有限的,当队列满了之后向里面生产日志可以有不同的策略,spdlog提供了三种策略:阻塞、丢弃新日志和丢弃旧日志。为方便实现这个需求,用循环队列来实现。
循环队列
循环队列的代码在circular_q.h中,实现起来不难。这里只提两点可能在没开始动手实现之前可能想不起来的点:
- circular_q应设计成类模板,使其能够支持各种数据类型;
- circular_q中实际存数据的std::vector<T> vec_的大小应该比circular_q能存的数据大小多一个,这样才能队列是满的还是空的,两个状态不会混淆。
多生产多消费的线程安全队列
这部分代码在mpmc_blocking_q.h中,我们先来看一下其中的成员变量:
class mpmc_blocking_queue
{
private:
std::mutex queue_mutex_;
std::condition_variable push_cv_;
std::condition_variable pop_cv_;
spdlog::details::circular_q<T> q_;
};push_cv_和pop_cv_是用来实现生产者消费者模型的关键,其存在的目的是当q_为空或满时,消费者线程或生产者线程是阻塞式等待,而不是空转。我们看看向mpmc_blocking_queue中生产和消费数据的代码:
void enqueue(T &&item)
{
{
std::unique_lock<std::mutex> lock(queue_mutex_);
pop_cv_.wait(lock, [this] { return !this->q_.full(); });
q_.push_back(std::move(item));
}
push_cv_.notify_one();
}
void dequeue(T &popped_item)
{
{
std::unique_lock<std::mutex> lock(queue_mutex_);
push_cv_.wait(lock, [this] { return !this->q_.empty(); });
popped_item = std::move(q_.front());
q_.pop_front();
}
pop_cv_.notify_one();
}spdlog线程池
站在数据(环形队列)的角度,线程池不断接收生产者(前端线程)输入的数据,同时不断从队列取出数据,交给消费者处理(后端线程)。
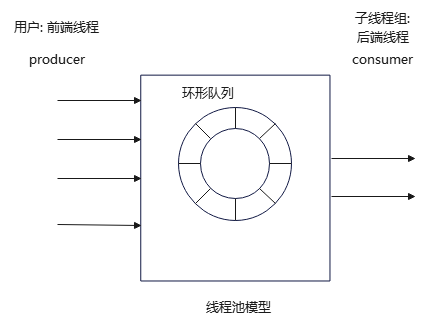
这里面包含几个重要线程池操作:
- 前端线程往线程池插入数据;
- 从线程池取出数据交给后端线程处理;
- 线程池数据满时,插入数据异常处理;
- 线程池空时,取出数据异常处理;
线程池的代码在thread_pool.h和thread_pool-inl.h中,这里的线程池跟那些通用的线程池实现相比,核心没变,每个线程都是负责从队列里面取东西然后执行,不同是线程池因为是专门做日志输出工作的,所以去从队列里去的东西是日志相关的东西,通用的线程池一般取的是函数指针。由于线程池的唯一需要确保线程安全的数据是环形队列,而环形队列本身提供线程安全支持,因此线程池无需额外支持线程安全。
简单看看每个线程(worker)做的事情:
void thread_pool::worker_loop_()
{
while (process_next_msg_()) { }
}
bool thread_pool::process_next_msg_()
{
async_msg incoming_async_msg;
q_.dequeue(incoming_async_msg);
switch (incoming_async_msg.msg_type) {
case async_msg_type::log: {
incoming_async_msg.worker_ptr->backend_sink_it_(incoming_async_msg);
return true;
}
case async_msg_type::flush: {
incoming_async_msg.worker_ptr->backend_flush_();
return true;
}
case async_msg_type::terminate: {
return false;
}
default: {
assert(false);
}
}
return true;
}上面的backend_sink_it_和backend_flush_里面的实现跟前面同步logger中的logger::sink_it_和logger::flush_是一样的。所以看到这就知道asyn_logger就是把其中调用sink这部分工作交给线程池来做了,仅此而已。
异步工厂方法
针对所使用的环形队列,当队列满时,如果插入数据,有两种策略:阻塞、非阻塞,分别对应工厂类型async_factory、async_factory_nonblock:
using async_factory = async_factory_impl<async_overflow_policy::block>; // 阻塞策略
using async_factory_nonblock = async_factory_impl<async_overflow_policy::overrun_oldest>; // 非阻塞策略可以看到上面2种工厂类型,都是通过async_factory_impl来实现的。那么,async_factory_impl是如何实现的呢?async_factory_impl也遵循工厂方法的潜规则:提供static create方法,根据模板参数Sink创建不同类型sink对象并绑定到新建的logger对象。
// async logger factory - creates async loggers backed with thread pool.
// if a global thread pool doesn't already exist, create it with default queue
// size of 8192 items and single thread.
template<async_overflow_policy OverflowPolicy = async_overflow_policy::block>
struct async_factory_impl
{
template<typename Sink, typename... SinkArgs>
static std::shared_ptr<async_logger> create(std::string logger_name, SinkArgs &&... args)
{
auto ®istry_inst = details::registry::instance();
// 如果全局线程池不存在,就创建一个
// create global thread pool if not already exists..
auto &mutex = registry_inst.tp_mutex();
std::lock_guard<std::recursive_mutex> tp_lock(mutex);
auto tp = registry_inst.get_tp();
if (tp == nullptr)
{
tp = std::make_shared<details::thread_pool>(details::default_async_q_size, 1U);
registry_inst.set_tp(tp);
}
auto sink = std::make_shared<Sink>(std::forward<SinkArgs>(args)...);
// 创建新async_logger对象同时, 绑定线程池
auto new_logger = std::make_shared<async_logger>(std::move(logger_name), std::move(sink), std::move(tp), OverflowPolicy);
registry_inst.initialize_logger(new_logger);
return new_logger;
}
跟同步工厂方法最大的区别是:异步工厂方法,是依附于一个(registry单例管理的)全局线程池的。创建出来的logger对象真实类型是派生类async_logger。而async_logger通过一个弱指针指向线程池。上面的只是工厂的类型,并非工厂方法。用户想要利用工厂方法创建对象,需要用到下面的create_async, create_async_nb方法:
// 采用阻塞策略的异步工厂方法
template<typename Sink, typename... SinkArgs>
inline std::shared_ptr<spdlog::logger> create_async(std::string logger_name, SinkArgs &&... sink_args)
{
return async_factory::create<Sink>(std::move(logger_name), std::forward<SinkArgs>(sink_args)...);
}
// 采用非阻塞策略的异步工厂方法
template<typename Sink, typename... SinkArgs>
inline std::shared_ptr<spdlog::logger> create_async_nb(std::string logger_name, SinkArgs &&... sink_args)
{
return async_factory_nonblock::create<Sink>(std::move(logger_name), std::forward<SinkArgs>(sink_args)...);
}
在客户端,比如你想创建一个basic_logger_mt,即一个基本都用于多线程环境的async_logger,可以这样封装工厂方法,然后供APP调用:
// include/spdlog/sinks/basic_file_sink.h
// 封装工厂方法,供APP调用
// factory functions
template<typename Factory = spdlog::synchronous_factory>
inline std::shared_ptr<logger> basic_logger_mt(
const std::string &logger_name, const filename_t &filename, bool truncate = false, const file_event_handlers &event_handlers = {})
{
return Factory::template create<sinks::basic_file_sink_mt>(logger_name, filename, truncate, event_handlers);
}
// APP端创建async_logger对象
// spdlog::init_thread_pool(32768, 1); // queue with max 32k items 1 backing thread.
auto async_file = spdlog::basic_logger_mt<spdlog::async_factory>("async_file_logger", "logs/async_log.txt");
sink
sink
sink相关的代码都在sinks文件夹中,有不同种类的sink实现,以满足用户对不同输出目的地的需求,比如有控制台、文件、网络、数据库等。
sink
| ---> base_sink ---> basic_file_sink
| ---> stdout_sink_basesink是所有不同类型sink的基类,它提供了统一的接口,实际上并它的实现并没有多少代码量。我们看看它的定义:
using level_t = std::atomic<int>;
class sink
{
public:
virtual ~sink() = default;
virtual void log(const details::log_msg &msg) = 0;
virtual void flush() = 0;
virtual void set_pattern(const std::string &pattern) = 0;
virtual void set_formatter(std::unique_ptr<spdlog::formatter> sink_formatter) = 0;
void set_level(level::level_enum log_level);
level::level_enum level() const;
bool should_log(level::level_enum msg_level) const;
protected:
// sink log level - default is all
level_t level_{level::trace};
};sink类只有一个成员变量,level_类型是原子变量。同时之后跟level_相关的成员函数在这里实现了,其他的都是纯虚函数,需要子类去实现。这是因为sink及其子类都要是线程安全的,因为此处level_已经是原子变量了,可以做到线程安全了,所以跟level_相关的成员函数就直接在此处得到实现。
其他成员函数log()和flush()的功能是将从logger传过来的msg转成字符串然后写到缓冲区和从缓冲区写到目的地(控制台、文件等)。set_pattern()和set_formatter()是用来设置日志格式的,例如显示时间的样式等,这两个函数一定程度上是等价的。具体是怎么格式化的,我们留到将formatter部分的时候再讲,本文不再展开。
既然sink及其子类都要求线程安全,那么就应该在sink这个基类这里把线程安全相关的代码都写好,这样子类继承时候再写的代码只管逻辑就行,不用再考虑线程安全问题了。这么想是对的,确实应该在父类中把线程安全相关的代码都写好,spdlog也是这么做的。但是是在base_sink类里实现的,而不是sink类。为什么是在base_sink类里,而不是在sink类里?以及为什么stdout_sink_base直接继承自sink而不是base_sink?
base_sink
base_sink继承自sink,而且是个类模板,代码也很少,就是对该加锁地方加上了锁,以此来实现线程安全。以下是base_sink部分代码:
template <typename Mutex>
class base_sink : public sink {
public:
void log(const details::log_msg &msg) final {
std::lock_guard<Mutex> lock(mutex_);
sink_it_(msg);
}
void flush() final {
std::lock_guard<Mutex> lock(mutex_);
flush_();
}
protected:
Mutex mutex_;
virtual void sink_it_(const details::log_msg &msg) = 0;
virtual void flush_() = 0;
};log和flush函数在sink是纯虚函数,需要在子类中实现。而base_sink的实现仅仅只是加锁之后再进一步调用sink_it_和flush_,只是做了线程安全方面的处理,没有具体业务逻辑。这里需要强调一下的是,锁mutex_的类型是Mutex是通过模板参数传进来的,也就是说base_sink是支持多种锁类型的。用模板来支持多种锁类型,这还不是这个模板用法的最值得说道的点。最值得说道的点是,这样的实现能够同时让base_sink十分优雅的支持无锁版本。
需要说明,对于只在单线程中使用spdlog,我们肯定不希望每次写日志还要加锁,毕竟这带来的白白的性能损耗,所以也必须给所有类型的sink至少提供有锁和无锁两种版本。
using basic_file_sink_mt = basic_file_sink<std::mutex>;
using basic_file_sink_st = basic_file_sink<details::null_mutex>;
struct null_mutex {
void lock() const {}
void unlock() const {}
};以上是basic_file_sink中的两行代码,basic_file_sink继承自Mutex。basic_file_sink_mt后面的mt就是multi-thread的意思,表示多线程版本,所以模板参数用的是std::mutex。basic_file_sink_st后面的st就是single-thread的意思,表示单线程版本,模板参数用的是details::null_mutex,这个null_mutex是spdlog自己实现的空锁,我的评价是妙啊。
basic_file_sink
接着上面,我们继续来看basic_file_sink的代码。就是把base_sink的两个纯虚函数sink_it_和flush_实现了,本身逻辑也是十分简单。
template <typename Mutex>
void basic_file_sink<Mutex>::sink_it_(const details::log_msg &msg) {
memory_buf_t formatted;
formatter_->format(msg, formatted);
file_helper_.write(formatted);
}
template <typename Mutex>
void basic_file_sink<Mutex>::flush_() {
file_helper_.flush();
}sink_it_中的formatter_->format(msg, formatted)就是将msg中的内容格式化成字符串,然后写入到formatted中。file_helper_.write和file_helper_.flush中的核心代码(ubuntu环境下)无非也就是std::fwrite和std::fflush两个库函数。
stdout_sinks
前面我们提到,stdout_sink_base直接继承自sink而不是base_sink。stdout_sink_base也是要考虑线程安全的,我们来看看它与base_sink有何不同。作为对比我们把base_sink的部分代码也贴过出来:
template <typename Mutex>
class base_sink : public sink {
protected:
Mutex mutex_;
};
template <typename ConsoleMutex>
class stdout_sink_base : public sink {
protected:
ConsoleMutex::mutex_t &mutex_;
};最大的区别就在于成员变量mutex_的类型不同,stdout_sink_base的锁类型是带引用的。因为stdout_sink_base就是输出到控制台,一个程序只能有一个控制台啊,因此stdout_sink_base中的mutex_应该是全局唯一的,是个单例,那么很理所当然的这里用引用类型。
struct console_mutex {
using mutex_t = std::mutex;
static mutex_t &mutex() {
static mutex_t s_mutex;
return s_mutex;
}
};
struct console_nullmutex {
using mutex_t = null_mutex;
static mutex_t &mutex() {
static mutex_t s_mutex;
return s_mutex;
}
};formatter
不在这里介绍,感兴趣可以好好学学C++20新增的format。
registry
spdlog主要由logger(也包括async_logger)、sink、formatter、registry这四个部分组成。实际上这三个已经足够将一条日志输出(记录)下来了,还剩下没介绍的registry则是负责管理前面那三个部件的。当然用户也可以不通过registry来自行管理。所以registry不是必须的,它本身的实现并不涉及spdlog的核心功能,只是为了更好的管理资源。例如通过registry,用户对所有logger设置日志等级、可以创建带有默认设置的logger之类的……
默认logger和默认sink
registry的代码主要在registry.h、registry-inl.h。还记得这一句最简单的使用spdlog的代码吗?
spdlog::info("Welcome to spdlog!");在这里我们既没有创建logger,也没有设置sink,直接就可用了。实际上是registry帮我们创建了默认的logger和默认的sink,方便我们直接使用。
template <typename T>
void info(const T &msg) { // 即spdlog::info
default_logger_raw()->info(msg);
}
spdlog::logger *default_logger_raw() {
return registry::instance().get_default_raw();
}
registry ®istry::instance() {
static registry s_instance;
return s_instance;
}
// 直接用logger的裸指针的原因,spdlog是这么解释的:
// To be used directly by the spdlog default api (e.g. spdlog::info)
// This make the default API faster
logger *registry::get_default_raw() {
return default_logger_.get();
}
registry::registry() {
auto color_sink = std::make_shared<sinks::ansicolor_stdout_sink_mt>();
const char *default_logger_name = "";
default_logger_ = std::make_shared<spdlog::logger>(default_logger_name,
std::move(color_sink));
}可以看到spdlog::info中default_logger_raw()得到了默认logger的指针,然后顺理成章就调用info输出日志。默认logger的指针则来自registry对象中的default_logger_成员变量。registry是单例,所以获取registry对象使用的是静态方法registry::instance()。最后我们看到registry::registry()中创建了默认logger,选择的sink是ansicolor_stdout_sink_mt,也就是彩色输出到控制台,最后的“_mt”表示是线程安全的sink。也就是说,当用户什么都没设置时调用spdlog::info时,结果是像控制台输出彩色日志,这也是用户刚上手spdlog最可能希望得到的结果。
logger工厂
registry主要作用就是管理logger(例如将所有logger日志等级、格式等统一为相同的),那么logger创建的时候就要将其共享指针存在registry中,这样registry才能管理到。在考虑到简单易用的原则,用户可以不事先了解logger和registry概念,也不必时刻记得要把logger的共享指针存到registry中。因此spdlog提供了一系列获取logger的函数,这些函数除了构造logger对象之外,还将这个logger的共享指针存到registry中。
// stdout_logger_mt返回使用stdout_sink的logger,且多线程版本(线程安全的)
template <typename Factory = spdlog::synchronous_factory>
std::shared_ptr<logger> stdout_logger_mt(....);
// basic_logger_st返回使用basic_file_sink的logger,且单线程版本(非线程安全的)
template <typename Factory = spdlog::synchronous_factory>
std::shared_ptr<logger> basic_logger_st(...);
// rotating_logger_mt返回使用rotating_file_sink的logger,且多线程版本(线程安全的)
template <typename Factory = spdlog::synchronous_factory>
std::shared_ptr<logger> rotating_logger_mt(...);spdlog几乎为所有类型的sink都提供了如上类似的logger创建函数。从函数名可以看出这类函数把sink的概念给隐藏了,普通用户只需要知道创建出来的logger能够把日志写到指定地方就行了,根本不需要知道sink这类东西的存在。我们以stdout_logger创建函数为例,看一下具体实现。
using stdout_sink_mt = stdout_sink<details::console_mutex>; // 有锁对应多线程版本
using stdout_sink_st = stdout_sink<details::console_nullmutex>; // 无锁对应单线程版本
// 模板参数Factory都默认为spdlog::synchronous_factory
template <typename Factory>
std::shared_ptr<logger> stdout_logger_mt(const std::string &logger_name) {
return Factory::create<sinks::stdout_sink_mt>(logger_name);
}
template <typename Factory>
std::shared_ptr<logger> stdout_logger_st(const std::string &logger_name) {
return Factory::create<sinks::stdout_sink_st>(logger_name);
}
struct synchronous_factory {
template <typename Sink, typename... SinkArgs>
static std::shared_ptr<spdlog::logger> create(std::string logger_name, SinkArgs &&...args) {
auto sink = std::make_shared<Sink>(std::forward<SinkArgs>(args)...);
auto new_logger = std::make_shared<spdlog::logger>(std::move(logger_name), std::move(sink));
details::registry::instance().initialize_logger(new_logger);
return new_logger;
}
};不论是stdout_logger_mt还是stdout_logger_st里面都直接调用了Factory::create。模板参数Factory都默认为spdlog::synchronous_factory,除此之外还可以是async_factory。
先看synchronous_factory::create的实现,这个函数里做的事情就是先把logger构造出来后,再传进registry的initialize_logger方法中,initialize_logger(new_logger)有做了一些初始化,例如将该logger的formatter(存在logger中的)设置为默认formatter(存在registry中的),因为用户大体上会希望新创建的logger能够在日志格式上在已有或者全局的基础上保持统一。同时initialize_logger(new_logger)也将该logger的shared_ptr存到registry中,这样用户就可以通过registry管理该logger。async_factory::create做的事情基本相同,需要额外做些事情主要就是async_logger中所使用的线程池的创建。这里使用工厂方法的重点不在在于重建对象或者更好的组织代码,而是在创建logger之后将其注册进registry,registry需要注册logger,所以才提供Factory来在创建logger后完成注册。

